

Deep Web i Dark Web: niewidoczne zasoby Internetu
Sieć powierzchniowa (Surface Web), z której użytkownicy Internetu korzystają na co dzień, składa się z zasobów, które wyszukiwarki mogą odnaleźć, a następnie zaoferować w odpowiedzi na zapytanie użytkownika. Jednak zasoby dostępne w wyszukiwarkach to tylko wierzchołek góry lodowej (ryc. 1) – tradycyjna wyszukiwarka indeksuje jedynie niewielką część danych. Pozostałe treści są zanurzone w tzw. głębokiej sieci (Deep Web).
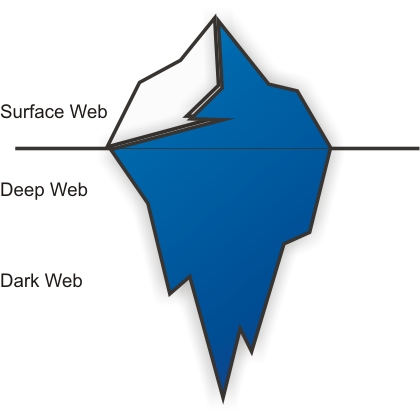 Rycina 1. Schemat wielowarstwowej dostępności zasobów w Internecie
Rycina 1. Schemat wielowarstwowej dostępności zasobów w Internecie
Źródło: opracowanie własne
Treści internetowe są znacznie bardziej zróżnicowane, a ich ilość jest zdecydowanie większa niż mogłoby się wydawać. Wielu użytkowników Internetu dociera jedynie do treści dostępnych za pośrednictwem najpopularniejszych wyszukiwarek, tymczasem większość treści jest generowanych dynamicznie, a standardowe wyszukiwarki ich nie indeksują. Dotarcie do nich wymaga określonej aktywności i konkretnych narzędzi [Bergman 2001].
Surface Web
Najbardziej powszechny i otwarty obszar sieci, który jest dostępny publicznie można nazwać „siecią powierzchniową” (Surface Web) czy też „powierzchnią sieci”. Gdy użytkownik szuka konkretnych informacji w Internecie przeważnie korzysta z wyszukiwarki. Wyniki wyszukiwania stanowią odpowiedź na zapytanie złożone z konkretnych słów kluczowych. Witryny (zasoby) znajdują swoje miejsce w wynikach wyszukiwania dzięki robotom indeksującym, które przeszukują zasoby Internetu i odnotowują odnalezione linki. W procesie indeksowania każdy zasób jest kategoryzowany. Oznacza to, że jeśli strona internetowa nie posiada linków prowadzących do niej, umieszczonych na innej stronie internetowej, robot wyszukiwarki jej nie odnajdzie [Sherman i Price 2003]. Widoczna sieć (Visible Web) składa się z witryn, które są dostępne dla ogółu społeczeństwa i które są zazwyczaj indeksowane przez wyszukiwarki. Obszar ten obejmuje wszystkie witryny, które można znaleźć za pomocą wyszukiwarek takich jak Google, Yahoo czy Bing.
Deep Web
Pierwsze wzmianki o „głębokiej sieci” (Deep Web) czy też „niewidocznej sieci” pojawiły się już 20 lat temu, kiedy zjawisko to było stosunkowo nowe, mało poznane i zaskakujące dla wielu użytkowników Internetu. Od tego czasu roboty indeksujące pokonały wiele barier technicznych, które uniemożliwiały im znalezienie „ukrytych” zasobów Internetu [UC Berkeley 2010]. Niewidoczny Internet to frakcja ustrukturyzowanych lub częściowo ustrukturyzowanych treści [Pederson 2013]. Invisible Web, niewidoczna sieć, znana również jako „undernet” czy też „hidden Web”, składa się z zasobów, które są trudne lub niemożliwe do znalezienia za pośrednictwem typowych wyszukiwarek i katalogów. Pomimo tego, że zasoby te pozostają poza zasięgiem tradycyjnych narzędzi wyszukiwania, stanowią one integralną, naturalną część sieci [Ehney i Shorter 2016].

Internet może być postrzegany jako ogromne repozytorium różnorodnych informacji lub encyklopedia z hasłami na każdy temat [Lin i Chen 2002]. Jednak standardowe wyszukiwarki uzyskują dostęp do niewielkiego odsetka informacji dostępnych w sieci. Głęboka sieć jest w pewnym sensie zawartością baz danych i innych usług internetowych, które z różnych powodów nie są indeksowane przez typowe wyszukiwarki. Roboty wyszukiwarek (tzw. „pająki” lub „szperacze”) nie zbierają informacji generowanych w czasie rzeczywistym, które mają charakter efemeryczny, takich jak dane wyświetlane na warstwach tematycznych map internetowych, wyniki wyszukiwania wyszukiwarek specjalistycznych, notowania giełdowe, aktualna pogoda w określonej lokalizacji lub rozkłady lotów linii lotniczych. Programy wyszukiwarek nie mogą wypełnić formularzy w celu wygenerowania określonych informacji. Wszystkie tego typu zasoby stanowią część głębokiej (niewidocznej) sieci [Avarikioti i in. 2018].
Rekordy baz danych „składane” w strony internetowe
Podczas gdy sieć powierzchniowa łączy miliardy stron HTML istnieje przekonanie, że znacznie więcej informacji jest „ukrytych” w głębokiej sieci, a dostęp do nich wymaga zapytania do baz danych. Takie informacje przeważnie nie są dostępne pod statycznym adresem URL – są one „składane” w strony internetowe jako forma odpowiedzi na zapytania przesłane za pośrednictwem interfejsu zapytań do bazy danych, np. utworzonych przy pomocy CGI, formularzy HTML lub JavaScript [He i in. 2007]. Bazy danych nie mogą być przeszukiwane i indeksowane przez silniki tradycyjnych wyszukiwarek, ponieważ nie mają statycznego adresu URL, który można byłoby umieścić w indeksie wyszukiwania. Ponieważ wyszukiwarki nie mogą obecnie skutecznie indeksować baz danych uważa się, że takie dane są „niewidoczne”, a zatem pozostają w dużej mierze „ukryte”. Są jednak kopalnią informacji, ponieważ wiele z nich zawiera szczegółowe i konkretne dane, których nie ma w innych częściach sieci [Lin i Chen 2002].
Wydobywanie zasobów
Duża część sieci jest ukryta przed robotami indeksującymi: witryny internetowe można wykluczyć z indeksowania przy pomocy pliku robots.txt. Wiele zasobów jest dostępnych po zalogowaniu się. Wszystkie te ograniczenia techniczne wykluczają z wyników wyszukiwania ogromne ilości informacji. Zjawiska te zrodziły charakterystyczne, metaforyczne zwroty określające dostępność informacji na „powierzchni sieci” lub w „widocznej sieci”, w sieci „głęboko ukrytej” lub „sieci niewidocznej” czy też sieci znajdującej się „pod spodem”. W różnych artykułach autorzy piszą o „drążeniu” w bazie danych, „zbieraniu” lub „oswajaniu” informacji [Devine i Egger-Sider 2004]. Metafory te nawiązują do górnictwa i „wydobywania” zasobów. Inne z kolei odwołują się do morskiej toni. Michael K. Bergman [2001] porównał przeszukiwanie Internetu do przeciągania sieci po powierzchni oceanu: wiele treści może zostać złapanych w sieci, lecz istnieje również wiele takich, które są dostępne na większej głębokości.

Wielu użytkowników uważa, że niewidzialna sieć nie jest warta uwagi, ponieważ jest pełna spamu i różnych treści efemerycznych. Tymczasem warto rozważyć jej eksplorację, choćby ze względu na mnogość i różnorodność zasobów, które zawiera. Zasoby w głębokiej sieci mają przeważnie wysoką jakość, są unikalne, mają charakter specjalistyczny i są gromadzone w jasno określonych obszarach tematycznych. Do zasobów dostępnych w Deep Web zalicza się m.in.: private web, disconnected page (unlinked content – witryny, do których nie prowadzą linki), contextual Web, dynamic content (treści generowane dynamicznie), limited access content (treści dostępne po zalogowaniu się) czy też non-HTML content [Chertoff i Simon 2015, Hurlburt 2017].
„Zakopany skarb sieci”
Niewidoczne zasoby obejmują treści, do których konwencjonalne wyszukiwarki, takie jak Google, Bing czy Yahoo! nie mają dostępu [Devine i Egger-Sider 2004]. Minkle [2002] nazwał takie zasoby „buried treasure of the web”. Głęboka część sieci nie jest całkowicie niewidoczna – jest niewidoczna tylko dla użytkowników konwencjonalnych wyszukiwarek internetowych [Ford i Mansourian 2006]. Pedley [2002] zwrócił uwagę na rozmiar i jakość informacji, które znajdują się w tym obszarze sieci. Sherman i Price [2003] pogrupowali niewidzialną sieć w cztery główne kategorie według przyczyn „niewidzialności zasobów”: (1) sieć nieprzezroczysta, (2) sieć prywatna, (3) sieć zastrzeżona oraz (4) prawdziwie niewidzialna sieć (the opaque, the private, the proprietary, and the truly invisible web) [Ford i Mansourian 2006]. Sherman and Price [2001] zauważyli, że niewidzialna sieć jest ogromna i rośnie szybciej niż Surface Web.
Prawdziwy rozmiar sieci
Obecnie w Internecie znajduje się ponad 1,5 miliarda stron internetowych. Spośród nich aktywnych jest mniej niż 200 milionów [Stats 2019]. Z Internetu korzysta około 3,5 miliarda użytkowników, co stanowi prawie 45% spośród 7-miliardowej populacji świata [Hurlburt 2017]. Widoczne zasoby World Wide Web stanowią jedynie od 6 do 10% całego Internetu. Pozostałe 90-94% to treści, które nie są indeksowane. Roboty wyszukiwarek nie docierają do większości zasobów zamieszczonych w głębokiej sieci, chociaż 95% z nich to publicznie dostępne informacje. Zasoby Internetu, które nie są indeksowane powiększają się gwałtownie i przyjmują przeważnie postać baz danych – ponad połowa niewidocznej sieci znajduje się w bazach danych specjalistycznych.

Deep Web charakteryzuje się rosnącą skalą, różnorodnością domen i licznymi ustrukturyzowanymi bazami danych [Khare i in. 2010]. Rośnie w tak szybkim tempie, że skuteczne oszacowanie jej wielkości może być trudne lub wręcz niemożliwe [Lu 2008]. Gulli i Signorini [2005] oszacowali wielkość Surface Web (public indexable web) na ok. 11,5 mld stron. Z tego zbioru 9,36 mld stron było dostępnych w indeksach czterech największych wyszukiwarek, w tym Google. Szacuje się, że rozmiar Invisible Web jest około 500 razy większy niż Surface Web. W 2001 roku Bergman oszacował, że Invisible Web zawiera prawie 550 miliardów pojedynczych dokumentów, podczas gdy Surface Web zawiera ich jedynie miliard. Badania te ujawniły, że Deep Web był około 400-500 razy większy od Surface Web [Bergman 2001]. Jednak kilka lat później wykazano, że szacunki te były wątpliwe [Lewandowski i Mayr 2006]. Według innych badań głęboka sieć składała się z około 307 000 witryn, 450 000 baz danych i 1 258 000 interfejsów i szybko się rozwijała, z 3-7-krotnym wzrostem w latach 2000-2004 [He i in. 2007]. Dzisiejszy Internet jest znacznie większy – szacuje się, że 555 milionów domen zawiera tysiące lub miliony unikalnych stron internetowych. Wraz z rozwojem sieci będzie się również powiększać zawartość Deep Web [Pederson 2013].
Głęboka sieć (Deep Web) bywa utożsamiana z ciemną siecią (Dark Web, Dark Net), przez co terminy te bywają używane zamiennie. Podczas gdy w głębokiej sieci można odnaleźć użyteczne informacje, Dark Web bywa przestrzenią dla działań nielegalnych i nieuczciwych.
Dark Web
Technologie internetowe zostały opracowane przy założeniu, że wszyscy użytkownicy Internetu są honorowi. Jednak „ciemna strona pojawiła się i zepsuła świat” [Kim i in. 2011]. Termin Deep Web jest używany do opisywania treści zamieszczonych w Internecie, które z różnych powodów nie są indeksowane przez wyszukiwarki. Dark Web jest częścią Deep Web, która została celowo ukryta i nie jest dostępna za pośrednictwem standardowych przeglądarek internetowych. Mroczna sieć to część Internetu, do której nie ma dostępu oprogramowanie głównego nurtu [Gehl 2016].

Dla wielu użytkowników Internet jest wspaniałym miejscem, narzędziem pracy, komunikacji i rozrywki. Jednak istnieją zakamarki sieci, które wydają się być odległe, a wiele z nich jawi się w mrocznych barwach. Określenie Dark Web przywodzi na myśl obrazy mrocznych zaułków, zatęchłych alei, niebezpiecznych osób i społecznie szkodliwych działań. Ciemna sieć to skryte, anonimowe miejsce, w którym szemrane typy oferują dostęp do nielegalnych towarów i usług [Bradbury 2014].
Ciemna sieć to tajemnicze miejsce. Większość użytkowników Internetu nie wie o jej istnieniu i nigdy tam nie trafi [Gollnick i Wilson 2016]. Dark Web jest częścią Internetu, do którego większość ludzi prawdopodobnie nie wie, jak uzyskać dostęp, i pewnie większość z nich nie chciałaby eksplorować treści, które są tam udostępniane [Jardine 2015]. Ciemna sieć jest miejscem, gdzie podejmowane są działania nielegalne – „cyberprzestępczość to rak, rozprzestrzeniający się z ciemnej sieci na resztę Internetu” [Hurlburt 2017].
Paradoksalnie Dark Web jest wyjątkowy, ponieważ nie jest szczególnie przyjazny dla użytkowników Internetu. Korzystanie z usług publicznych takich jak np. Facebook czy Twitter wymaga założenia konta, co zajmuje kilka minut. Dostęp do zasobów umieszczonych w Dark Net nie jest taki prosty. Korzystanie z ciemnej sieci nierzadko wymaga szyfrowania i deszyfrowania wiadomości oraz umiejętności posługiwania się stosunkowo ezoteryczną (krypto)walutą wirtualną. Co oczywiste, żadne z miejsc w ciemnej sieci nie jest reklamowane, poza tym, że wiele z nich bywa demonizowanych w mediach [Maddox i in. 2016]. Wszystko to sprawia, że z przeglądarki Tor, która umożliwia dostęp do ciemnej sieci korzysta relatywnie niewielu (wyspecjalizowanych) użytkowników. Badania pokazały, że w Stanach Zjednoczonych w 2015 roku odnotowano 55 użytkowników mostu Tor (Tor bridge users) na 100 000 użytkowników Internetu, natomiast w Kanadzie odnotowano 79 użytkowników na 100 000 użytkowników Internetu [Jardine 2015].
The Onion Router
Dark Web wykorzystuje protokuł Onion Router (The Onion Router hidden service protocol). Tor i inne podobne sieci umożliwiają użytkownikom przebywanie w sieci w niemal całkowitej anonimowości poprzez szyfrowanie pakietów danych i wysyłanie ich przez kilka węzłów sieciowych (onion routers) [Chertoff i Simon 2015]. The Onion Router (Tor) jest zarówno wolnym oprogramowaniem, jak i otwartą siecią, która pomaga użytkownikom pozostać anonimowymi i bronić się przed analizą ruchu [Cardullo 2015].

Ciemna sieć jest przedstawiana jako miejsce, gdzie ukrywane są nielegalne treści i jednocześnie miejsce, które zapewnia całkowitą wolność (słowa) [Gehl 2016]. Tor może być wykorzystywany w celu ominięcia mechanizmów filtrowania treści, cenzury i innych ograniczeń komunikacyjnych. Ponadto istotną cechą Tora jest możliwość hostowania stron internetowych anonimowo, co zapewnia pewną dozę bezkarności. Wydawcy, którzy prowadzą „ciemne strony internetowe” (z końcówką .onion), są w stanie ukryć swoją tożsamość i lokalizację przed użytkownikami Internetu [Dingledine i in. 2004]. W większości przypadków użytkownicy witryn z końcówką .onion nie znają tożsamości hosta, a host nie zna tożsamości użytkowników. To odróżnia Tor od typowego Internetu, w którym witryny są powiązane z firmą lub lokalizacją, a odwiedzający są często identyfikowani i monitorowani za pomocą różnych technologii śledzenia, takich jak cookie, rejestracje kont, adresy IP czy geolokalizacja [Gehl 2016].
Tor jest zasadniczo neutralnym narzędziem, które może być używane zarówno w słusznej sprawie, jak i w celach przestępczych. Niektórzy użytkownicy cenią anonimowość Tora, ponieważ utrudnia ona cenzurowanie witryn lub treści, które mogą być przechowywane w innym miejscu świata [Owen i Savage 2015]. Jednak te same narzędzia open-source, które zapewniają ochronę prywatności i umożliwiają ominięcie cenzury, stają się przestrzenią dla czarnych rynków i napędzają działalność przestępczą [Hurlburt 2017]. Tor jest przeważnie używany w celach przestępczych w krajach liberalnych, podczas gdy swoje „dobre zastosowania” znajduje w krajach, gdzie panują represje polityczne [Jardine 2015]. Przykładowo państwo rosyjskie zaoferowało 110 tys. dolarów (£65,000) osobie lub organizacji, która złamie szyfrowanie i anonimowość sieci Tor [BBC 2014].
Dark Web słynie z nielegalnych treści. Czy słusznie?
Pomimo, że Dark Web zawiera także nieszkodliwe treści (np. serwisy osób, które uważają, że wolność słowa jest zagrożona), słynie z treści nielegalnych. Dark Net jest przestrzenią, gdzie rozwija się cyfrowy czarny rynek, umożliwiający zakup danych wrażliwych (personalnych), usług, przedmiotów, produktów i substancji o ograniczonej dostępności np. narkotyków. Jaskrawym przykładem jest kryptomarket Silk Road, miejsce nielegalnego handlu narkotykami [Maddox i in. 2016].
Ciemna sieć może być źródłem zagrożeń zarówno dla prywatnych osób, jaki i dla przedsiębiorstw. Ta mroczna strona Internetu jest przestrzenią, gdzie skradzione dane to chodliwy towar – podrobione i skradzione dokumenty są od dawna sprzedawane w ciemnej sieci [Sixgill 2018]. Wiele skradzionych informacji, w tym numerów kart kredytowych, dokumentów finansowych, danych logowania, zastrzeżonego kodu źródłowego, dokumentów podatkowych lub innych wrażliwych danych, można pozyskać w ciemnej sieci, gdzie przyciągają nabywców chcących otworzyć fałszywe konta, ujawnić luki w oprogramowaniu, skraść własność intelektualną lub dopuścić się innych oszustw. Tylko w 2018 roku odnotowano 2216 potwierdzonych naruszeń danych, a 76% z nich miało motywację finansową (wg Verizon 2018 Data Breach Investigations Report) [Terbium Labs 2018].

Mroczne rynki internetowe obiecują niewykrywalne, anonimowe transakcje. Transakcje wykonywane w Dark Web opierają się na kryptowalutach, które zapewniają anonimowość kupującym i sprzedającym [Maddox i in. 2016]. Bitcoin, zdecentralizowana, międzynarodowa waluta działająca w oparciu o technologie peer-to-peer [Barratt 2012], dotychczas najczęściej używana waluta w Dark Net, jest szybko zastępowana przez kryptowalutę Monero [Hurlburt 2017]. Adresy transakcji realizowanych przy pomocy Monero są ukryte, przez co znalezienie nadawców i odbiorców jest niezwykle trudne. Możliwe jest także ukrycie kwoty przelewu. Monero używa sygnatur pierścieniowych, przekazuje poufne transakcje i ukrywa adresy aby zaciemnić źródła, kwoty i miejsca docelowe wszystkich transakcji.
Podczas gdy ciemna sieć jest często demonizowana badania pokazały, że jest ona miejscem gdzie występują przede wszystkim legalne, a nawet przyziemne treści. Badania przeprowadzone w australijskiej sieci Tor w zbiorze 232 792 stron zamieszczonych na 7651 wirtualnych domenach Tor, pozwoliły zidentyfikować szerokie spektrum materiałów, które się w niej znajdowały – od nielegalnych po wręcz banalne [Dalins i in. 2018]. Nie oznacza to jednak, że ciemna sieć jest bezpieczna. Inne badania pokazały, że nielegalne treści zamieszczone w Dark Web, były zdominowane przez narkotyki i różne nielegalne usługi. Jednocześnie jednak treści legalne stanowiły 53,4% wszystkich przebadanych domen (ryc. 2) i 54,5% wszystkich adresów URL (ryc. 3) [Gollnick i Wilson 2016].
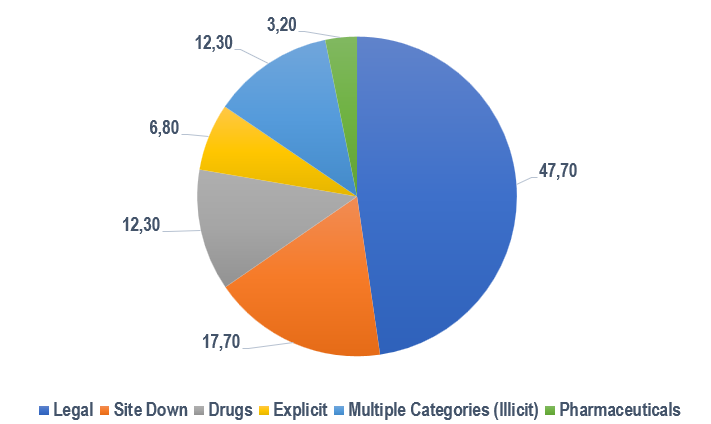 Rycina 2. Total content (by URL)
Rycina 2. Total content (by URL)
Źródło: opracowanie własne na podstawie [Gollnick i Wilson 2016]
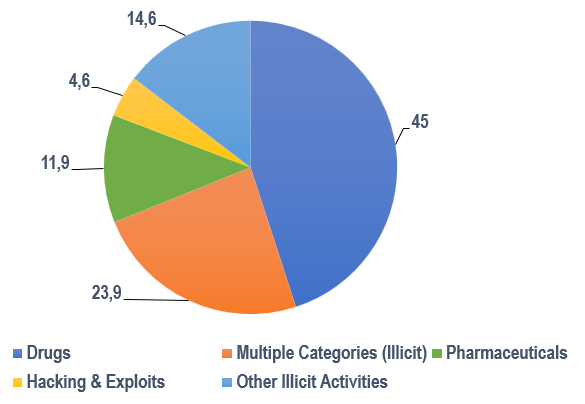 Rycina 3. Illicit content (by URL)
Rycina 3. Illicit content (by URL)
Źródło: opracowanie własne na podstawie [Gollnick i Wilson 2016]
Avarikioti i współautorzy wykazali, że wbrew powszechnym opiniom, widoczna część darknetu jest zaskakująco dobrze połączona za pośrednictwem stron centralnych, takich jak wiki i fora. Przeprowadzili oni kompleksową kategoryzację treści i wykazali, że około połowa widocznych „ciemnych treści” dotyczyła legalnych działań. Pozostałe treści były związane m.in. ze sprzedażą podrobionych towarów lub narkotyków [Avarikioti i in. 2018].
Przykład Silk Road
2 października 2013 roku, w oddziale biblioteki w San Francisco, agenci federalni zatrzymali administratora internetowego rynku kryminalnego Silk Road (online black market), podczas gdy on był zalogowany do witryny Silk Road za pośrednictwem tymczasowo zaszyfrowanego połączenia Tor, wykorzystując sieć Wi-Fi biblioteki publicznej. Od momentu uruchomienia witryny w styczniu 2011 roku ponad 100 000 użytkowników wykorzystało ją do zakupu nielegalnych towarów, w tym narkotyków o wartości 1,2 mld USD [Hurlburt 2017]. Maddox i współautorzy [2016] tuż przed zamknięciem Silk Road przeprowadzili anonimowe wywiady online z 17 osobami, które zgłosiły zakup leków na Silk Road* (v1.0). Większość uczestników badania stwierdziła, że ich działania w ciemnej sieci są oddzielone od ich codziennego życia. Rzadko ujawniali oni fakt zażywania narkotyków i swojej aktywności na czarnych rynkach Dark Net z powodu obaw o bezpieczeństwo osobiste i stygmatyzację społeczną [Maddox i in. 2016]. Dla użytkowników Dark Web Silk Road nie był tylko rynkiem handlu narkotykami: ułatwiał wspólne doświadczenie wolności osobistej w ramach libertariańskich ram filozoficznych, gdzie otwarte dyskusje na temat stygmatyzowanych zachowań były inspirowane i wspierane [Chertoff i Simon 2015].
* Silk Road (v2.0) reaktywował się w ciągu miesiąca od zamknięcia jego pierwszej odsłony. FBI potrzebował kolejnego roku na odnalezienie kolejnego administratora i serwerów [Mac 2014]. Więcej o przypadku SilkRoad napisał Eric Jardine [2015].
Podsumowanie
Większość danych branżowych, danych wysokiej jakości tj. zebranych według zweryfikowanej, uznanej metodologii, często też recenzowanych (zweryfikowanych), znaleźć można w głębokiej sieci. Są to przeważnie dane, które znajdują specjalistyczne zastosowanie. Z głębokiej sieci wydobywane są także dane „mniej patetyczne”, codziennego użytku, jak choćby dane meteorologiczne.
Dotarcie do ciemnej sieci jest znacznie łatwiejsze niż mogłoby się wydawać, choć w ciemnej sieci nie ma nic, co powinno interesować przeciętnego użytkownika Internetu. Przeglądanie zasobów ciemnej sieci to proszenie się o kłopoty, jeśli jest wykonywane w nieodpowiedni sposób.
Źródła
- Avarikioti, G., Brunner, R., Kiayias, A., Wattenhofer, R., Zindros, D. (2018). Structure and Content of the Visible Darknet. arXiv preprint arXiv:1811.01348.
- Barratt, M.J. (2012). Silk Road: eBay for drugs. Addiction, 107(3), 683-683. https://doi.org/10.1111/j.1360-0443.2011.03709.x
- BBC (2014). Russia Offers $110,000 to Crack Tor anonymous Network. BBC News, https://www.bbc.com/news/technology-28526021
- Bergman, M.K. (2001). White paper: the deep web: surfacing hidden value. Journal of Electronic Publishing, 7(1). http://dx.doi.org/10.3998/3336451.0007.104
- Bradbury, D. (2014). Unveiling the dark web. Network Security, 2014(4), 14-17. https://doi.org/10.1016/S1353-4858(14)70042-X
- Cardullo, P. (2015). ‘Hacking multitude’ and Big Data: Some insights from the Turkish ‘digital coup’. Big Data & Society, 2(1), 1-14. https://doi.org/10.1177/2053951715580599
- Chertoff, M., Simon, T. (2015). The impact of the dark web on internet governance and cyber security. Global Commission on Internet Governance Paper Series, No. 6.
- Dalins, J., Wilson, C., Carman, M. (2018). Criminal motivation on the dark web: A categorisation model for law enforcement. Digital Investigation, 24, 62-71. https://doi.org/10.1016/j.diin.2017.12.003
- Devine, J., Egger-Sider, F. (2004). Beyond Google: the invisible web in the academic library. The Journal of Academic Librarianship, 30(4), 265-269. https://doi.org/10.1016/j.acalib.2004.04.010
- Dingledine, R., Mathewson, N., Syverson, P. (2004). Tor: The second-generation onion router. Naval Research Lab Washington DC.
- Ehney, R., Shorter, J.D. (2016). Deep web, dark web, invisible web and the post ISIS world. Issues in Information Systems, 17(4), 36-41.
- Ford, N., Mansourian, Y. (2006). The invisible web: an empirical study of “cognitive invisibility”. Journal of Documentation, 62(5), 584-596. https://doi.org/10.1108/00220410610688732
- Gehl, R.W. (2016). Power/freedom on the dark web: A digital ethnography of the Dark Web Social Network. New Media & Society, 18(7), 1219-1235. https://doi.org/10.1177/1461444814554900
- Gollnick, C., Wilson, E. (2016). Separating Fact from Fiction: The Truth about the Dark Web. Terbium Labs.
- Gulli, A., Signorini, A. (2005). The indexable web is more than 11.5 billion pages. In Proceedings of the 14th international conference on World Wide Web (WWW) – Special interest tracks and posters, 902-903.
- He, B., Patel, M., Zhang, Z., Chang, K. C. C. (2007). Accessing the deep web: A survey. Communications of the ACM, 50(5), 94-101.
- Hurlburt, G. F. (2017). Shining Light on the Dark Web. IEEE Computer, 50(4), 100-105. https://doi.org/10.1109/MC.2017.110
- Jardine, E. (2015). The Dark Web dilemma: Tor, anonymity and online policing. Global Commission on Internet Governance Paper Series, No. 21.
- Khare, R., An, Y., Song, I. Y. (2010). Understanding deep web search interfaces: A survey. ACM SIGMOD Record, 39(1), 33-40.
- Kim, W., Jeong, O. R., Kim, C., So, J. (2011). The dark side of the Internet: Attacks, costs and responses. Information systems, 36(3), 675-705. https://doi.org/10.1016/j.is.2010.11.003
- Lewandowski, D., Mayr, P. (2006). Exploring the academic invisible web. Library Hi Tech, 24(4), 529-539. https://doi.org/10.1108/07378830610715392
- Lin, K.I., Chen, H. (2002). Automatic information discovery from the invisible Web. In Proceedings. International Conference on Information Technology: Coding and Computing (pp. 332-337). IEEE.
- Lu, J. (2008). Efficient estimation of the size of text deep web data source. In Proc. of the 17th ACM Conference on Information and Knowledge Management CIKM ’08. ACM Press, New York, NY.
- Mac, R. (2014). Feds Shutter Illegal Drug Marketplace Silk Road 2.0, Arrest 26-Year-Old San Francisco Programmer. Forbes.
- Maddox, A., Barratt, M. J., Allen, M., Lenton, S. (2016). Constructive activism in the dark web: cryptomarkets and illicit drugs in the digital ‘demimonde’. Information, Communication & Society, 19(1), 111-126. https://doi.org/10.1080/1369118X.2015.1093531
- Minkle, W. (2002), The invisible web. School Library Journal, 49(12), 29.
- Owen, G., Savage, N. (2015). The Tor dark net. Global Commission on Internet Governance Paper Series, No. 20.
- Pederson, S. (2013). Understanding the Deep Web in 10 minutes. BrightPlanet. Whitepaper.
- Pedley, P. (2002). Why you can’t afford to ignore the invisible web. Business Information Review, 19(1), 23-31.
- Sherman, C., Price, G. (2001). The Invisible web: Uncovering Information Sources Search Engines Can’t See, CyberAge Books, Medford, NJ.
- Sherman, C., Price, G. (2003). The invisible web: uncovering sources search engines can’t see. Library Trends, 52(2), 282-298.
- Sixgill (2018). Forging Documents in the Deep and Dark Web. Sixgill Report.
- Stats (2019). Total number of Websites. Internet Live Stats, http://www.internetlivestats.com/total-number-of-websites/
- Terbium Labs (2018). A Buyer’s Guide to Dark Web Monitoring. Six Questions to Ask When Developing a Dark Web Intelligence Strategy. Terbium Labs.
- UC Berkeley (2010). Invisible or Deep Web: What it is, How to find it, and Its inherent ambiguity. University of California, Berkeley. Teaching Library Internet Workshops, http://bit.ly/2DDaoZ0